- Home
- About Us
- Service
- Application
- Technology
- Resource
- Contact Us

LIUDUS®
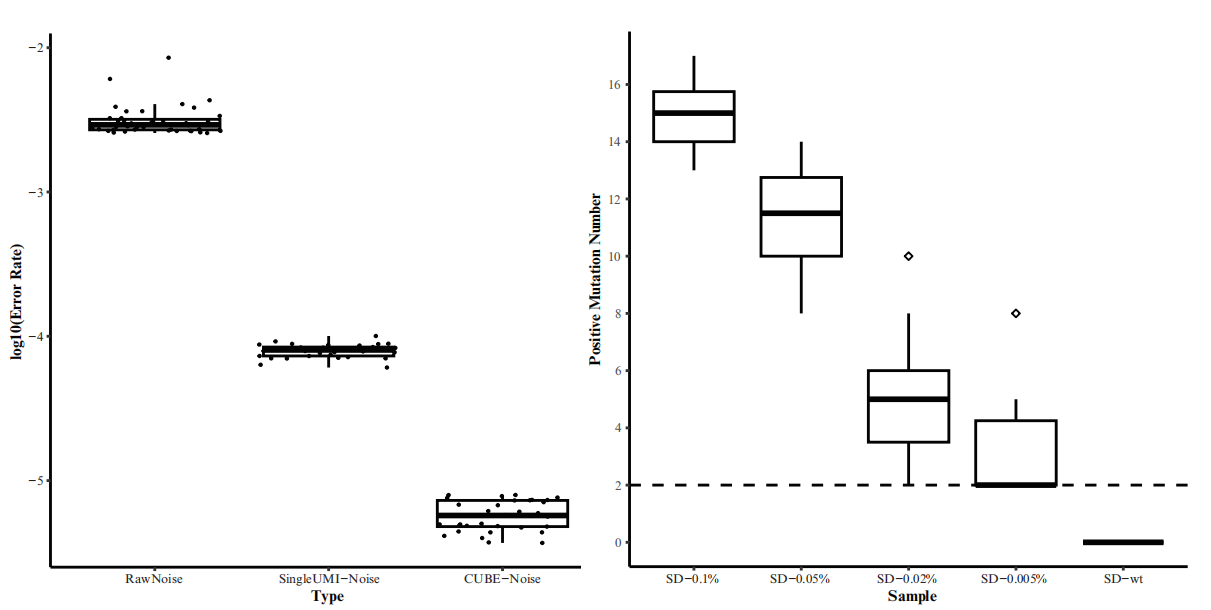
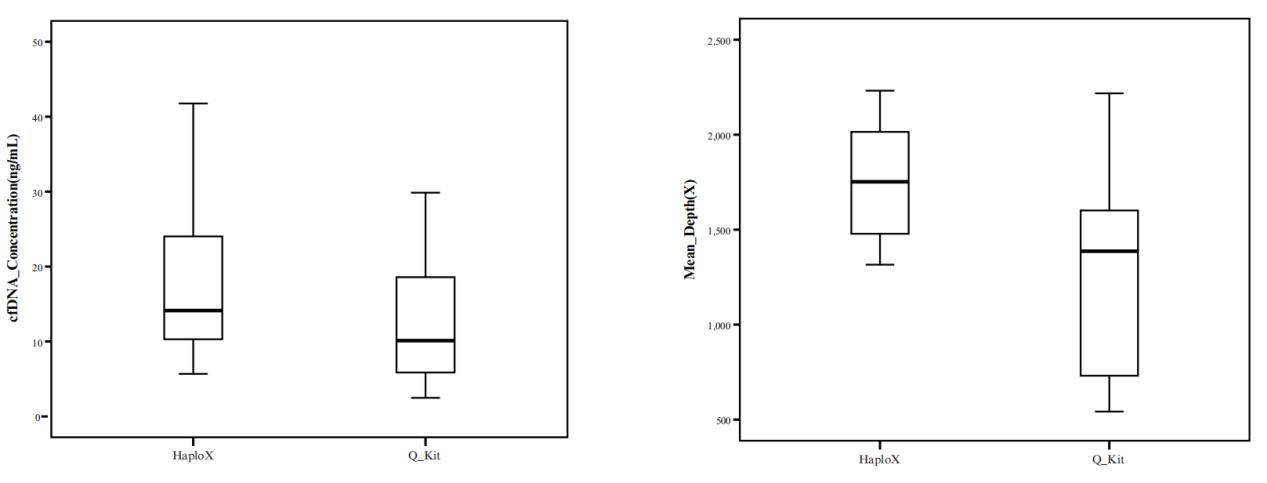
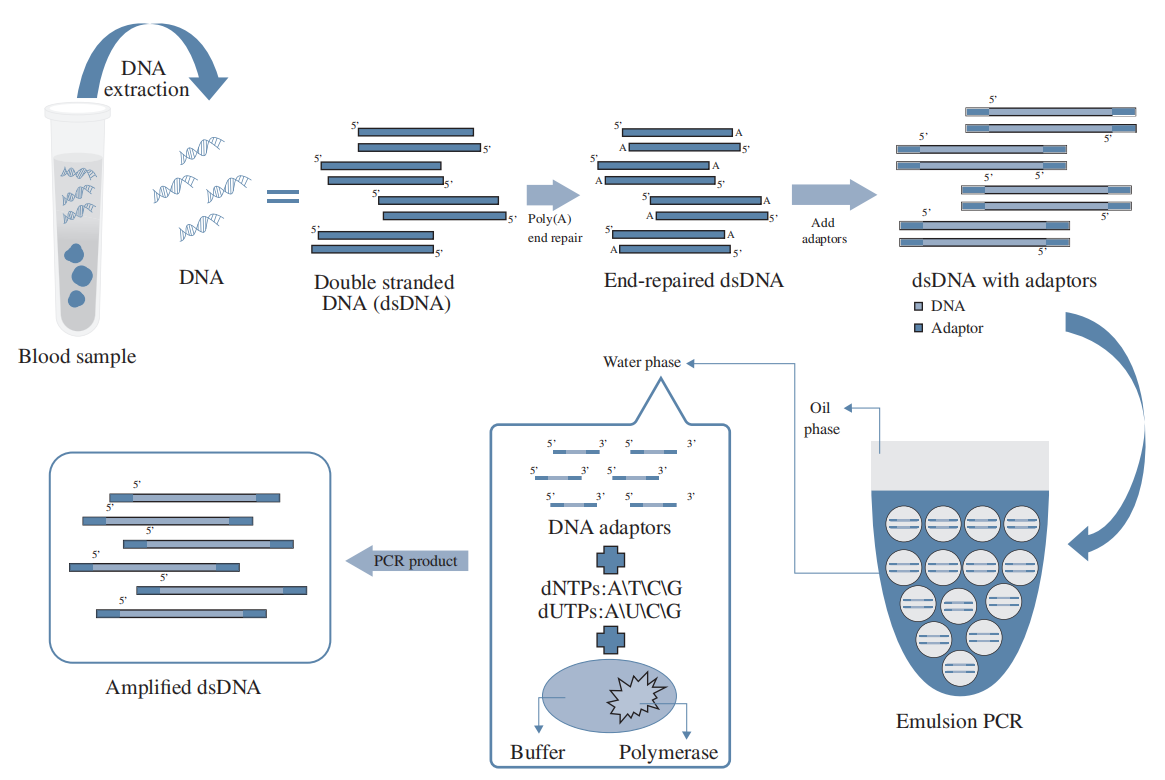

HaploX has meticulously developed an end-to-end IT infrastructure that forms the backbone of our digital, automated, and smart laboratory operations.
01
HapLab®
Comprehensive Laboratory Information Management System
HapLab® integrates HaploX’s proprietary molecular technologies and in-house bioinformatics tools under the LIUDUS®. This LIMS system ensures seamless, information-based, closed-loop management of our entire NGS workflow. HapLab® consists of four core modules:
1. Order Management Module:
• Manages systematic accession and tracking of clinical samples.
• Ensures sample integrity and proper chain of custody.
2. Wet Lab Workflow Management Module:
• Automates project resourcing and organization of experimental workflows.
• Reduces user intervention, increases wet lab efficiency, and maintains data integrity.
3. Bioinformatics Analysis Module:
• Executes complex multi-step bioinformatics workflows with automatic parallel analysis.
• Enhances analysis efficiency.
4. Report Interpretation Module:
• Integrates multidimensional patient information.
• Facilitates data management and mining at both patient and population levels.
02
HapYun®
Advanced Cloud Platform for Data Management
HapYun® is our proprietary one-stop cloud platform designed for efficient and scalable data management, storage, analysis, and delivery. Key features of HapYun® include:
• A rich library of modular, out-of-the-box pipelines and tools for various molecular diagnostics applications.
• Efficient, customizable analysis of high-throughput genomics data at scale.
• Automatic task execution, real-time operation logs, and performance monitoring.
By embedding these advanced systems, HaploX ensures superior efficiency, accuracy, and scalability in genetic testing, reinforcing our commitment to cutting-edge molecular diagnostics.